In this blog, we will see how to use with Stata and Python. I will rely on two previous blogs showing how to use Using DBnomics with Stata and Python and DBnomics with Stata. This time, we use the dbnomics package to import the Trade Openness indicator maintained by the World Bank (https://db.nomics.world/WB/WDI?q=NE.TRD.GNFS.ZS).
Key takeaways:
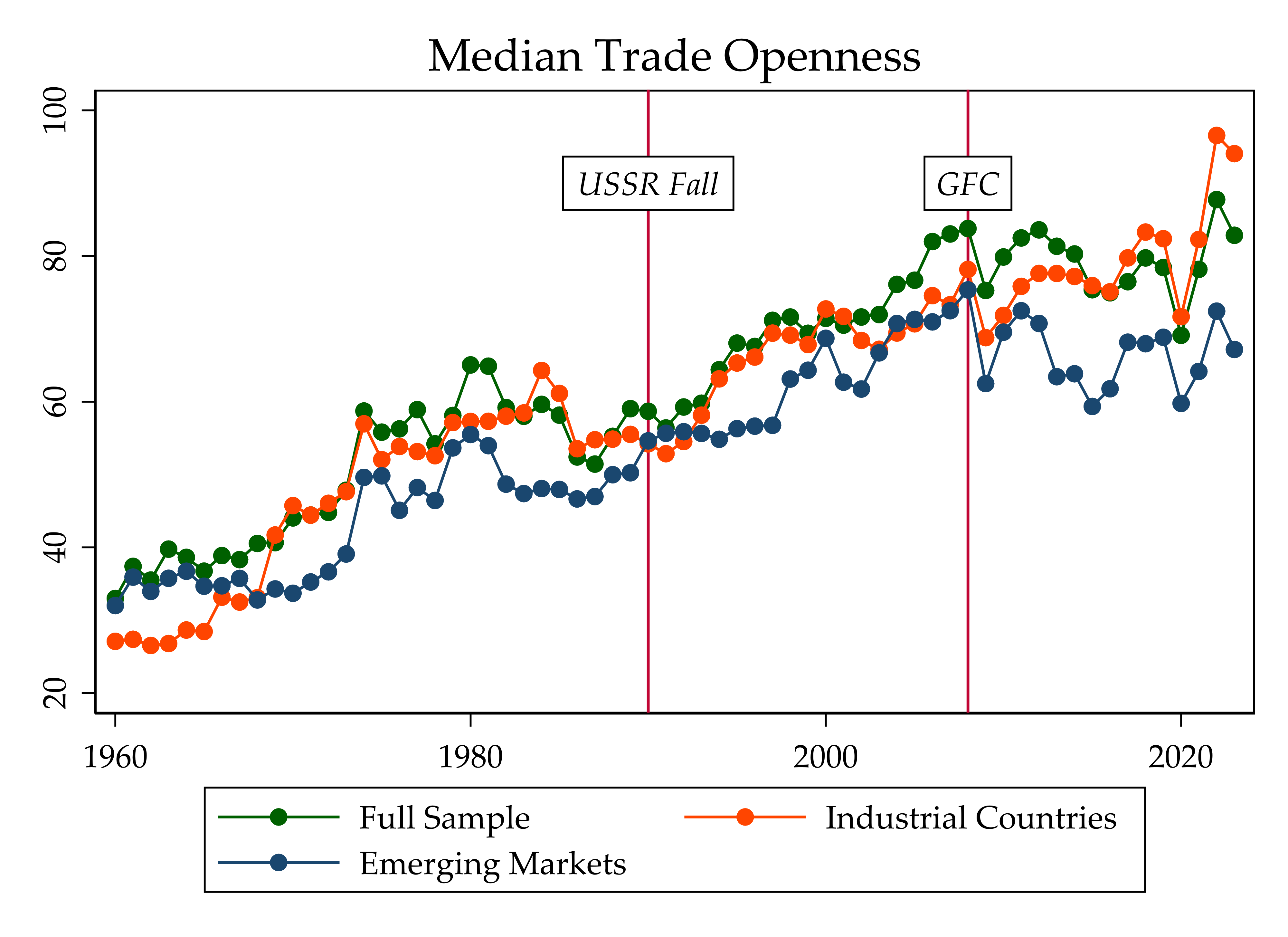
- The glory days of globalization, with an increasing trade openness, may be dated between 1990 and 2008;
- “Covid-19 [may have been] the ‘Last Nail’ in the Coffin of Globalization”, as argued by Carmen M. Reinhart;
- Median Trade Openness has stalled after the global financial crisis in 2008-09, possibly reflecting the Slowbalisation;
- Two episodes of trade collapse have been observed during the the global financial crisis in 2008-09 and during the pandemic crisis in 2020;
- Using Python to download data from API links is faster than using Stata DBnomics package;
- ChatGPT 5 is pretty good at translating Stata DBnomics syntax into Python DBnomics syntax;
- The syntax to import World Bank Data is a bit different from the one for IMF data;
- Using Python and Stata from the same do-file is pretty good;
- I plan to extend to other previous Stata blogs and integrate more Python in future blogs on coding.
We are going to replicate the first step of the following blog, Merging datasets with different country codes with Stata with a different series, using Python, and reproduce the figure below:
The code is commented at each steps below:
// Clear the consol and the dataset
cls
clear
// Choose the dir folder (optional)
cd "C:\Users\jamel\Dropbox\stata\dbnomics_python"
**# Python
**# Only once locate and initiate python
python search
*python set exec "C:/Users/jamel/AppData/Local/Programs/Python/Python313/python.exe", permanently
**# Use python to install DBnomics
python:
import sys, subprocess
subprocess.check_call([sys.executable, "-m", "pip", "install", "--upgrade", "dbnomics"])
end
/*
python:
import sys, subprocess
subprocess.check_call([sys.executable, "-m", "pip", "install", "--upgrade", "pandas"])
end
*/
**# Download data from DBnomics
/*
// Stata version
dbnomics import, provider(WB) dataset(WDI) ///
indicator("NE.TRD.GNFS.ZS") clear
*/
// Python version (and deactivate future warnings)
python:
import dbnomics as db
import warnings; warnings.filterwarnings("ignore", category=FutureWarning, module=r"dbnomics")
df = db.fetch_series(
'WB', 'WDI',
dimensions={'frequency': ['A'], 'indicator': ['NE.TRD.GNFS.ZS']},
max_nb_series=10000
)
df.to_excel('NE_TRD_GNFS_ZS.xlsx', index=False)
print(df.shape) # quick sanity check
end
// Python version with the API on DBnomics (select columns) and create the excel file
python:
import dbnomics as db
api_link = ("https://api.db.nomics.world/v22/series/WB/WDI"
"?observations=1&limit=1000"
"&dimensions=%7B%22indicator%22%3A%5B%22NE.TRD.GNFS.ZS%22%5D%2C%22frequency%22%3A%5B%22A%22%5D%7D")
df = db.fetch_series_by_api_link(api_link, max_nb_series=10000)
df[["country","original_period","value","country (label)"]].to_excel("NE_TRD_GNFS_ZS_2.xlsx", index=False)
print("Saved NE_TRD_GNFS_ZS_2.xlsx | shape:", df.shape, "| series:", df['series_code'].nunique())
end
**# Use Stata to read the dataset
import excel NE_TRD_GNFS_ZS_2.xlsx, firstrow clear
/*
drop frequency provider_code dataset_code dataset_name ///
series_code series_name FREQ INDICATOR ///
Frequency Indicator
*/
/*
// Use kountry and perpare the dataset
*ssc install kountry
kountry REF_AREA, from(iso2c)
rename NAMES_STD name
replace name="United Arab Emirates" if imfcode==466
replace name="Serbia" if imfcode==965
drop if imfcode==.
drop period
drop original_value
*/
*ssc install kountry
kountry country, from(iso3c) to(imfn)
rename _IMFN_ imfcode
drop if imfcode==.
rename original_period period
rename value TRADOPEN
rename countrylabel name
order imfcode name period
// Prepare the data
destring period, replace
xtset imfcode period
xtdes
// Create the country groups (requires the ado-file 'group_dummy')
rename imfcode cn
group_dummy
rename cn imfcode
gen OPENidc=TRADOPEN if idc==1
gen OPENemg=TRADOPEN if emg==1
lab var TRADOPEN "Full Sample"
lab var OPENidc "Industrial Countries"
lab var OPENemg "Emerging Markets"
// Use lpgraph to draw time series graph with panel data
*ssc install lgraph
set scheme s1color
graph set window fontface "Palatino Linotype"
lgraph TRADOPEN OPENidc OPENemg period, wide ///
ti("Median Trade Openess") xti("") yti("") ///
note("`Note: Data from the WB.'") xline(1990 2008) ///
text(90 2008 "{it:GFC}", box margin(small) fc(white)) ///
text(90 1990 "{it:USSR Fall}", box margin(small) fc(white)) ///
name(TradOpen, replace) s(p50)
graph export TradOpen.png, as(png) width(4000) Further reading
Aizenman, J., & Ito, H. (2020). Global politics from the view of the political-economy trilemma, 7 Aug 2020, VoxEU.org, https://cepr.org/voxeu/columns/global-politics-view-political-economy-trilemma
Ward, J. (2020). Pandemic is [the] last nail in globalization’s coffin, says Carmen Reinhart. Bloomberg. May 21, 2020, https://www.hks.harvard.edu/centers/mrcbg/programs/growthpolicy/reinhart-says-covid-19-last-nail-coffin-globalization-carmen
Raciborski, R. (2008). kountry: A Stata Utility for Merging Cross-country Data from Multiple Sources. The Stata Journal, 8(3), 390–400. https://doi.org/10.1177/1536867X0800800305
1 Comment
[…] see how to use with Stata and Python. I will rely on three previous blogs showing how to use Using DBnomics with Stata and Python (World Bank Data), Using DBnomics with Stata and Python, and DBnomics with Stata. This time, we use the dbnomics […]