In this blog, we will see how to merge two datasets with different county code in a few simple steps. In my previous blog, I have shown how to use DBnomics with Stata. This time, we use the dbnomics package to import the newly Financial Development index built by the International Monetary Fund (https://db.nomics.world/IMF/FDI)
(A) In a first step, I download the kountry package and the Financial Development Index
cd "C:\Users\jamel\Dropbox\stata\"
cd "blog\kountry"
ssc install kountry
dbnomics data, pr(IMF) d(FDI) clear
dbnomics import, pr(IMF) d(FDI) ///
sdmx(A..FD_FD_IX) clearYou can see that the series use a two-digit country code, AM is for Armenia and AO is for Angola
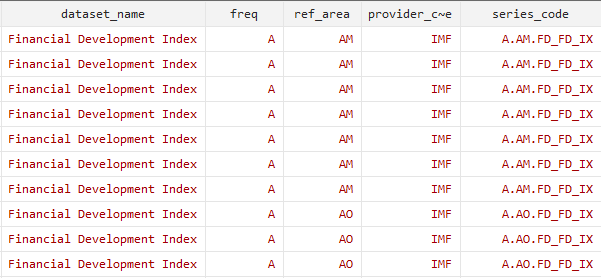
I remove the unnecessary information in the following
drop period_start_day frequency dataset_code ///
dataset_name freq indicator indexed_at provider_code ///
series_code series_numHowever, the “series_name” variable is not in a very convenient format
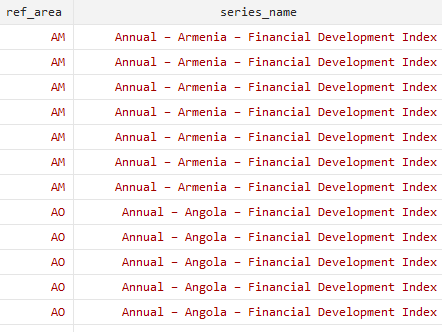
I split the “series_names” variable with the parse command, which is quite useful. I found the symbol “–” in the “series_names” variable
split series_name, parse(–)The “series_names” variable is now split into three components and I will use the information in the “series_name2” variable
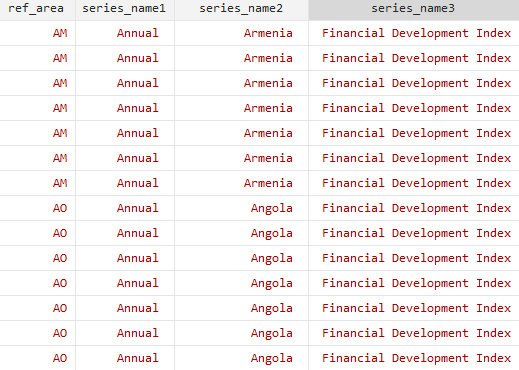
Now, I remove some information and I save the data in the current directory
order series_name2 ref_area period value ///
series_name1 series_name3, first
drop series_name series_name1 series_name3
encode series_name2, generate(country)
drop series_name2
order country ref_area, first
rename value fd
drop if period<=2000
drop if period>=2021
save fd, replace(B) In a second step, I will use the World Bank’s cross-country database of fiscal space as an example of a dataset with other formats for the country codes
https://www.worldbank.org/en/research/brief/fiscal-space
(C) The last step before merging the datasets is to use a country list where you have selected a sample of countries and periods. Here, I have a sample of 110 countries observed during 20 years from 2001 to 2020
(D) The last step is to use the kountry package to decode the country code and produce standardized country names in the three datasets. I start the country list that use three-digit codes (option iso3c)
use country-list, clear
rename year period
kountry countrycode, from(iso3c)
save country-list-k, replace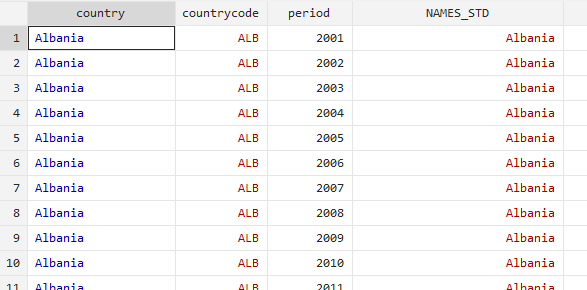
Now, I decode the country codes for the Financial Development Index (option iso2c)
use fd.dta, clear
kountry ref_area, from(iso2c)
save fd-k, replace
I merge the two previous datasets, the name of the Master file comes after “use” and the name of the Using file comes after ‘using’. I can see that the data has been merged except for one country. There are no data for the Financial Development Indicator for Iraq
use country-list-k, clear
merge 1:1 NAMES_STD period using fd-k
drop if _merge==2
drop _merge
save country-list-fd, replace

Now, I will keep the general government gross debt in the fiscal space database and decode the IFS country code with the option “imfn”
use Fiscal-space-data, clear
keep ccode ifscode country year ggdy
kountry ifscode, from(imfn)
encode country, generate(country_)
drop country
rename country_ country
order country ccode ifscode year ggdy NAMES_STD
rename year period
drop if period<=2000
drop if period>=2021
save Fiscal-space-data-k, replace
I merge the databases and save the results in an Excel file called “Merged Database”
use country-list-fd, clear
merge 1:1 NAMES_STD period using Fiscal-space-data-k
drop if _merge==2
drop _merge
drop NAMES_STD
sort countrycode period
export excel using "Merged Database", ///
firstrow(variables) replace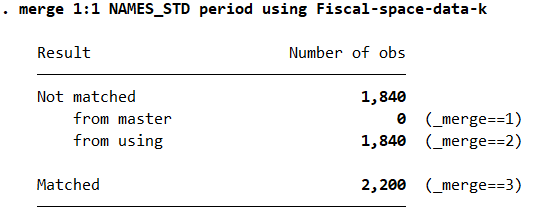
Finally, all the files are available in the following ZIP archive
Further reading
Raciborski, R. (2008). kountry: A Stata Utility for Merging Cross-country Data from Multiple Sources. The Stata Journal, 8(3), 390–400. https://doi.org/10.1177/1536867X0800800305
7 Comments
[…] are going to replicate the first step of the following blog, Merging datasets with different country codes with Stata with a different series, using Python, and reproduce the figure […]
[…] are going to replicate the first step of the following blog, Merging datasets with different country codes with Stata with a different series, using Python, and reproduce the figure […]
[…] are going to replicate the first step of the following blog, Merging datasets with different country codes with Stata, using Python and reproduce the figure […]
Thanks
Pleasure is mine!
[…] Merging datasets with different country codes with Stata […]
[…] Merging datasets with different country codes with Stata […]