Let me show you how to use DBnomics to build databases at the NUTS 0, NUTS 1, NUTS 2 levels. I recommend you to consult my blog series on DBnomics before delving into this blog.
First, you have to choose the current directory where your files will be saved. I can use the global command to select a specific folder. You can change that to your own folder:
cls
clear
global Docs = "C:\Users\jamel\Documents\GitHub\"
global Proj = "EconMacroBlog\DBnomics_NUTS2"
cd "${Docs}"
cd "${Proj}"Then, I have to select on DBnomics which series will be used in my dataset. In my example, I will use the Compensation of employees and the Employment (thousand hours worked) in this example. See the corresponding pages on the DBnomics website:
Then, I use the dbnomics package to retrieve the data. In the dataset option, I put the name of the Eurostat code of the series. The CN variable is created, with the substr() function, in order to have the level of aggregation. Indeed, the country code has 2 letters at the NUTS 0 level (country level), 3 letters at the NUTS 1 level and 4 letters at the NUTS 2 levels:
**#*** Compensation of employees by NUTS 2 regions *************
dbnomics import, provider(Eurostat) dataset(nama_10r_2coe) ///
sdmx(A.MIO_EUR.TOTAL.) clear
rename value COMP
destring COMP, replace force
split series_name, parse(–)
encode series_name4, generate(cn)
keep cn geo period COMP
order cn geo period COMP
gen CN = substr(geo,1,2)
encode geo, generate(GEO)
xtset GEO period
xtdes
tsfill, full
drop if period<2000
drop if period>2019
tsfill, full
xtdes
gen COUNT=length(geo)
label var COMP "Compensation of employees in Millions of EUR"Thanks to the COUNT variable, I create a dataset for each level of aggregation and I save the whole database:
// Run everything between preserve and restore
preserve
keep if COUNT==2
tsfill, full
xtdes
save comp_eurostat_NUTS_0.dta, replace
restore
// Run everything between preserve and restore
preserve
keep if COUNT==3
tsfill, full
xtdes
save comp_eurostat_NUTS_1.dta, replace
restore
// Run everything between preserve and restore
preserve
keep if COUNT==4
tsfill, full
xtdes
save comp_eurostat_NUTS_2.dta, replace
restore
save comp_eurostat.dta, replace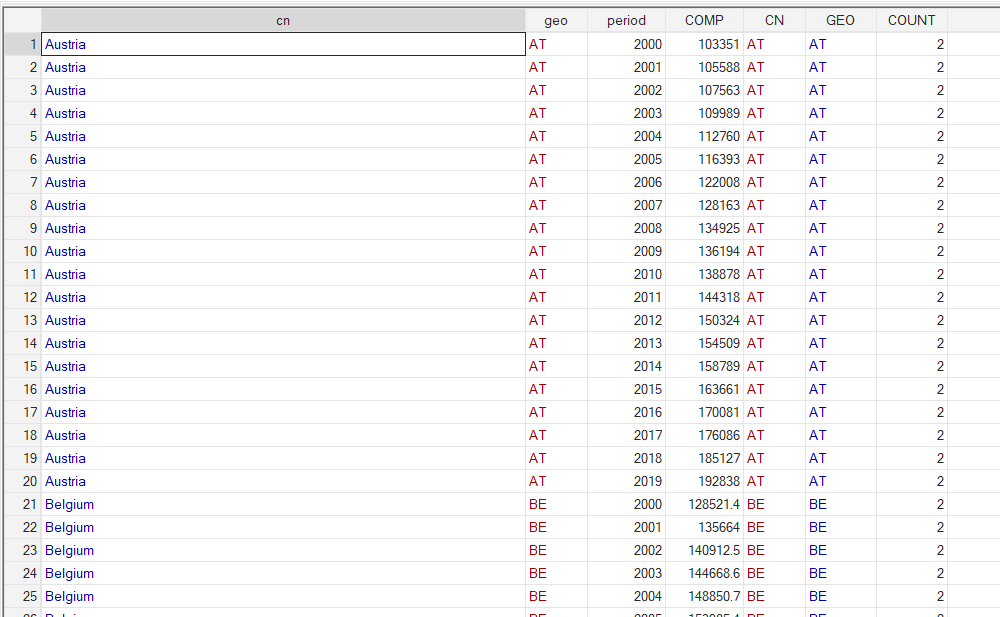
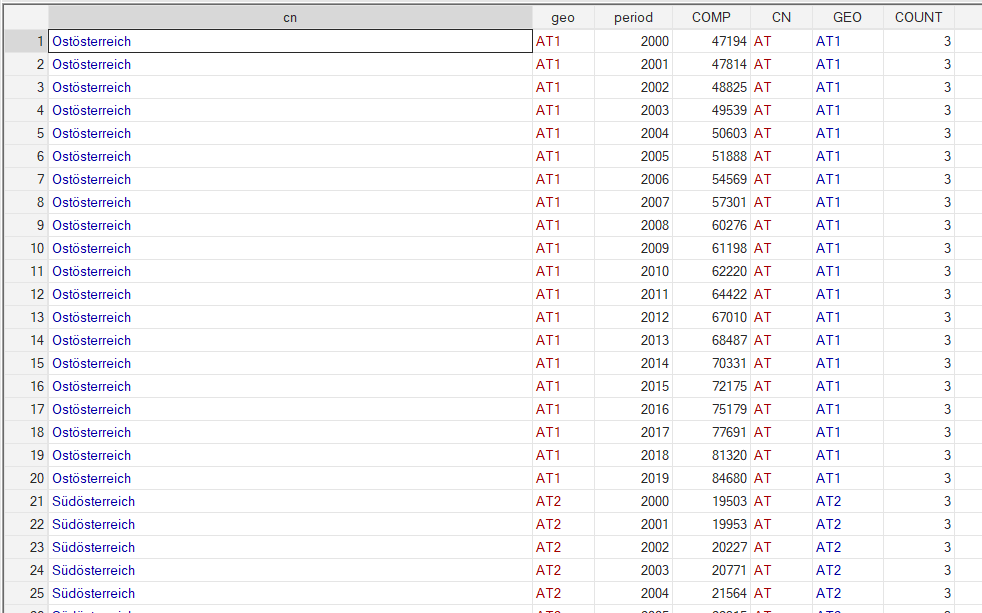
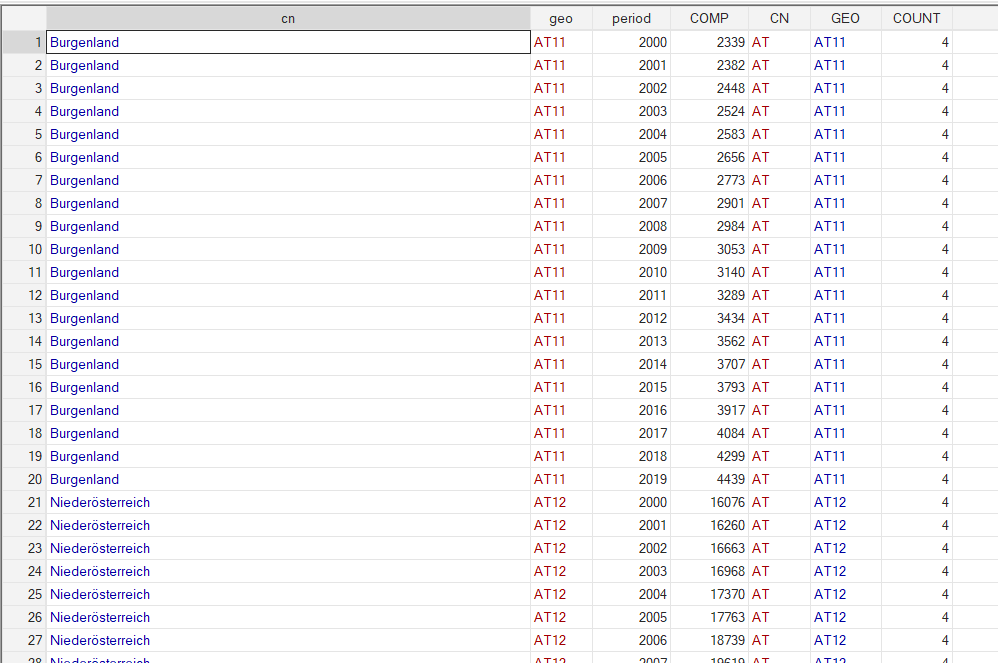
I repeat the same process for the second variable in this example:
**#*** Employment (thousand hours worked) by NUTS 2 regions ****
dbnomics import, provider(Eurostat) dataset(nama_10r_2emhrw) ///
sdmx(A.THS.EMP.TOTAL.) clear
rename value HOURS
destring HOURS, replace force
split series_name, parse(–)
encode series_name4, generate(cn)
keep cn geo period HOURS
order cn geo period HOURS
gen CN = substr(geo,1,2)
encode geo, generate(GEO)
xtset GEO period
xtdes
tsfill, full
drop if period<2000
drop if period>2019
tsfill, full
xtdes
gen COUNT=length(geo)
label var HOURS "Employment (thousand hours worked)"
// Run everything between preserve and restore
preserve
keep if COUNT==2
tsfill, full
xtdes
save hours_eurostat_NUTS_0.dta, replace
restore
// Run everything between preserve and restore
preserve
keep if COUNT==3
tsfill, full
xtdes
save hours_eurostat_NUTS_1.dta, replace
restore
// Run everything between preserve and restore
preserve
keep if COUNT==4
tsfill, full
xtdes
save hours_eurostat_NUTS_2.dta, replace
restore
save hours_eurostat.dta, replace
Finally, I merge the data. You can repeat the process if you want to add more series:
**# Merge ******************************************************
use comp_eurostat.dta, replace
xtdes
foreach v in hours_eurostat {
merge 1:1 GEO period using `v'.dta, ///
keep(1 3) nogen
}
order cn geo GEO CN period COMP HOURS, first
label var COUNT "Length of the geo code"
// Run everything between preserve and restore
preserve
keep if COUNT==2
tsfill, full
xtdes
save dataset_eurostat_NUTS_0.dta, replace
restore
// Run everything between preserve and restore
preserve
keep if COUNT==3
tsfill, full
xtdes
save dataset_eurostat_NUTS_1.dta, replace
restore
// Run everything between preserve and restore
preserve
keep if COUNT==4
tsfill, full
xtdes
save dataset_eurostat_NUTS_2.dta, replace
restore
**# *** End of the program *************************************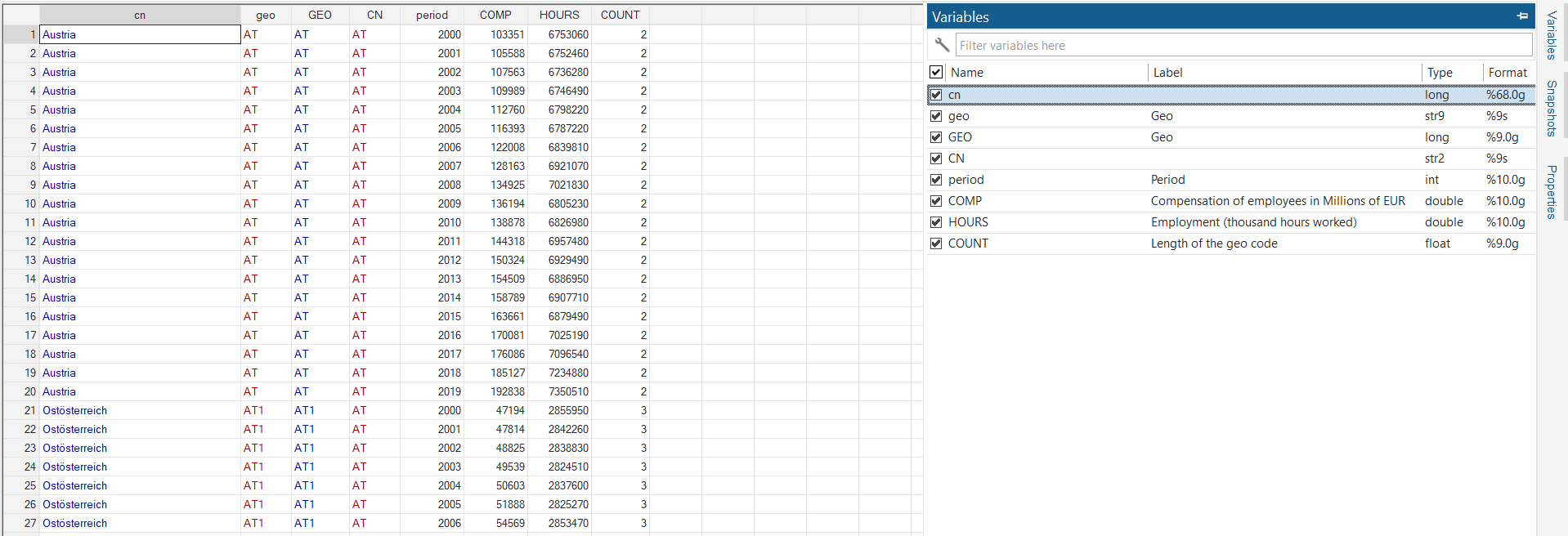
As we have seen in this blog, it is possible to build databases at different levels of aggregation using NUTS data. The files for replicating the results in this blog are available on my GitHub.
2 Comments
[…] maps with Stata for the NUTS regions NUTS Data with DBnomics Drawing maps with Stata for the NUTS regions (Hourly […]
[…] Drawing maps with Stata for the NUTS regions NUTS Data with DBnomics […]