When you are interested in geopolitical risks, up to some point you will heard about the GDELT project:
Here, the brief description on their website:
A Global Database of Society
Supported by Google Jigsaw, the GDELT Project monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day, creating a free open platform for computing on the entire world.
In this blog, I will show how to use the R Package ‘GDELTtools’ to extract data for the action performed by ‘Actor1’ upon ‘Actor2’. I am extremely grateful to Hanh My Le (Technische Universität Braunschweig, Institut für Volkswirtschaftslehre) for signaling me the package after the 2024 annual meeting of the European Public Choice Society. I start by installing and loading the package:
install.packages("GDELTtools")
library(GDELTtools)Then, I will use the GDELT command to specify the Actor1 and the Actor2. In my example, Actor1 will be the US and Actor2 will be China. I chose the date of the first Clinton-Trump debate:
data <- GetGDELT(start_date="2016-09-26", end_date="2016-09-26",
row_filter=Actor1Code=="USA" & Actor2Code=="CHN",
contains("date"), starts_with("actor"))In the lines above, I specified the names of the Actors and kept the variables that contain “date” and start with “actor”. In this case, I have access to 37 variables:
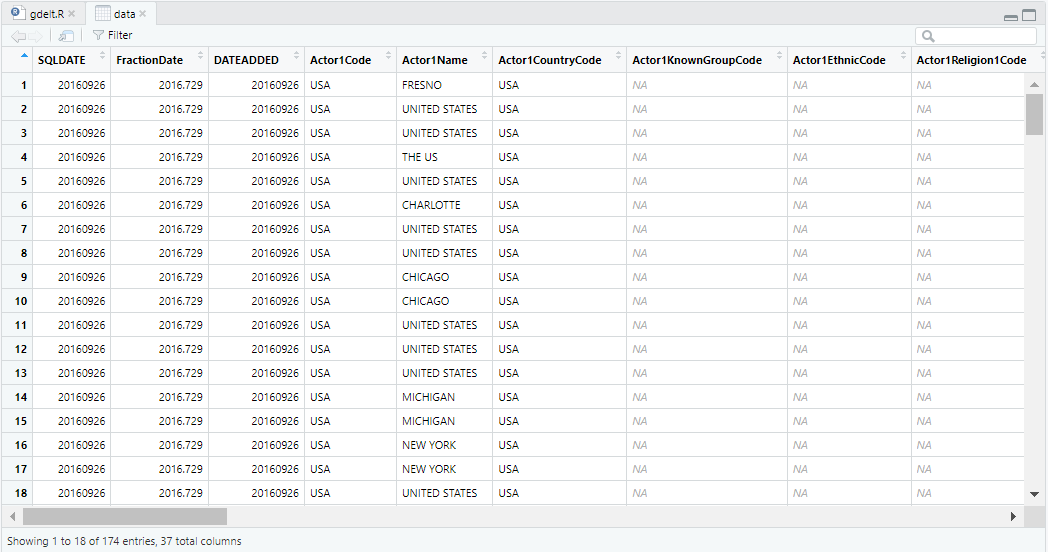
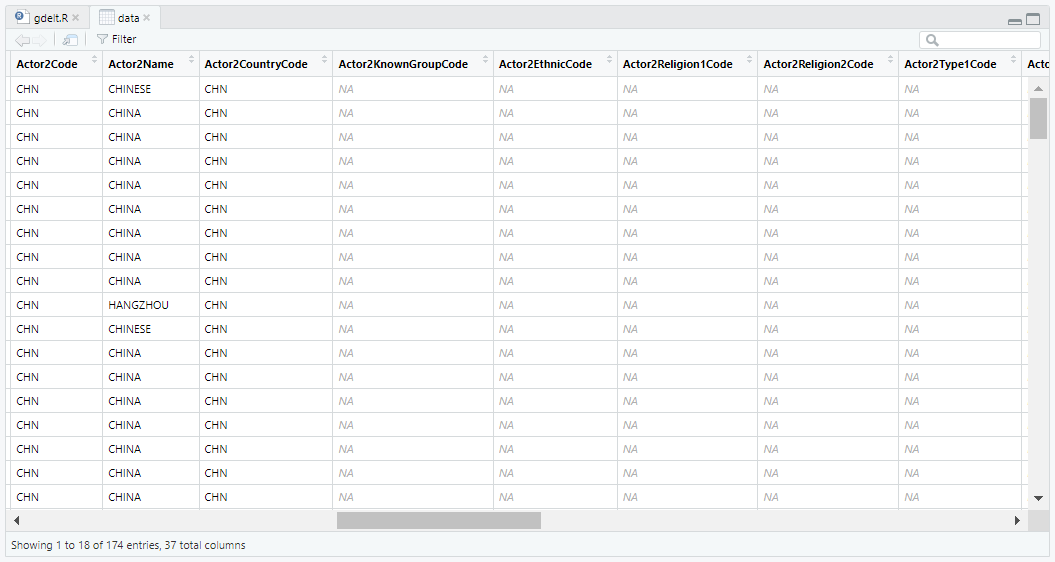
At the same time, I can also be interested in more information. So, instead of restricting the search, I can relax some restriction in the following code. The complete list of the variables and their definition is available in the last version of the GDELT codebook.
data1 <- GetGDELT(start_date="2016-09-26", end_date="2016-09-26",
row_filter=Actor1Code=="USA" & Actor2Code=="CHN")
Now, I have access to interesting information like the Goldstein score and the Average tone:
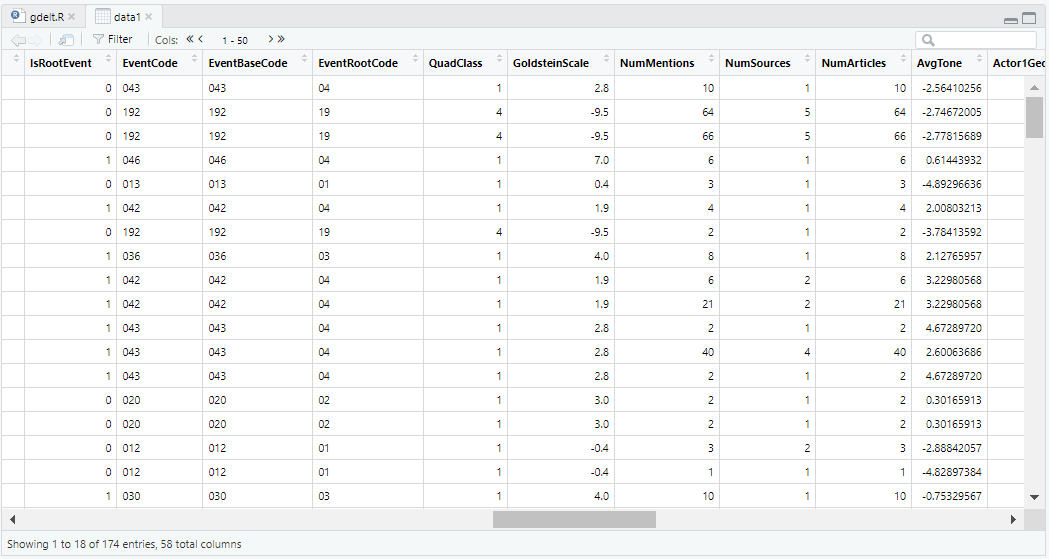
Besides, a nice implementation of these data in a research paper can be found here. Finally, I save my data in Excel files:
library(xlsx)
write.xlsx(data, "C:/Users/jamel/Documents/GitHub/EconMacroBlog/Start_GDELT_Data")
write.xlsx(data1, "C:/Users/jamel/Documents/GitHub/EconMacroBlog/Start_GDELT_Data")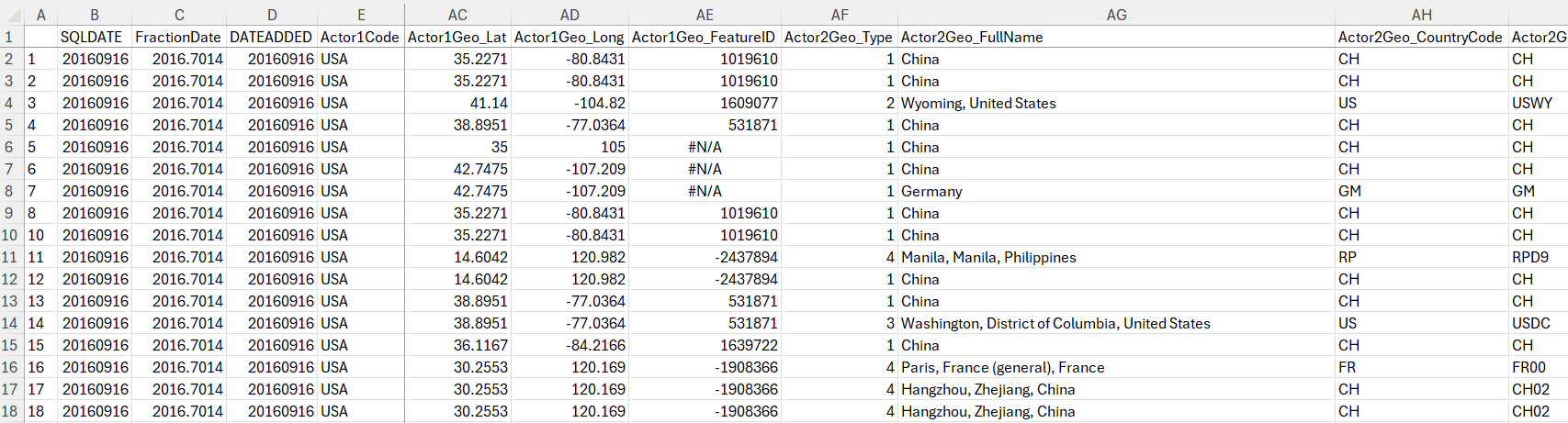
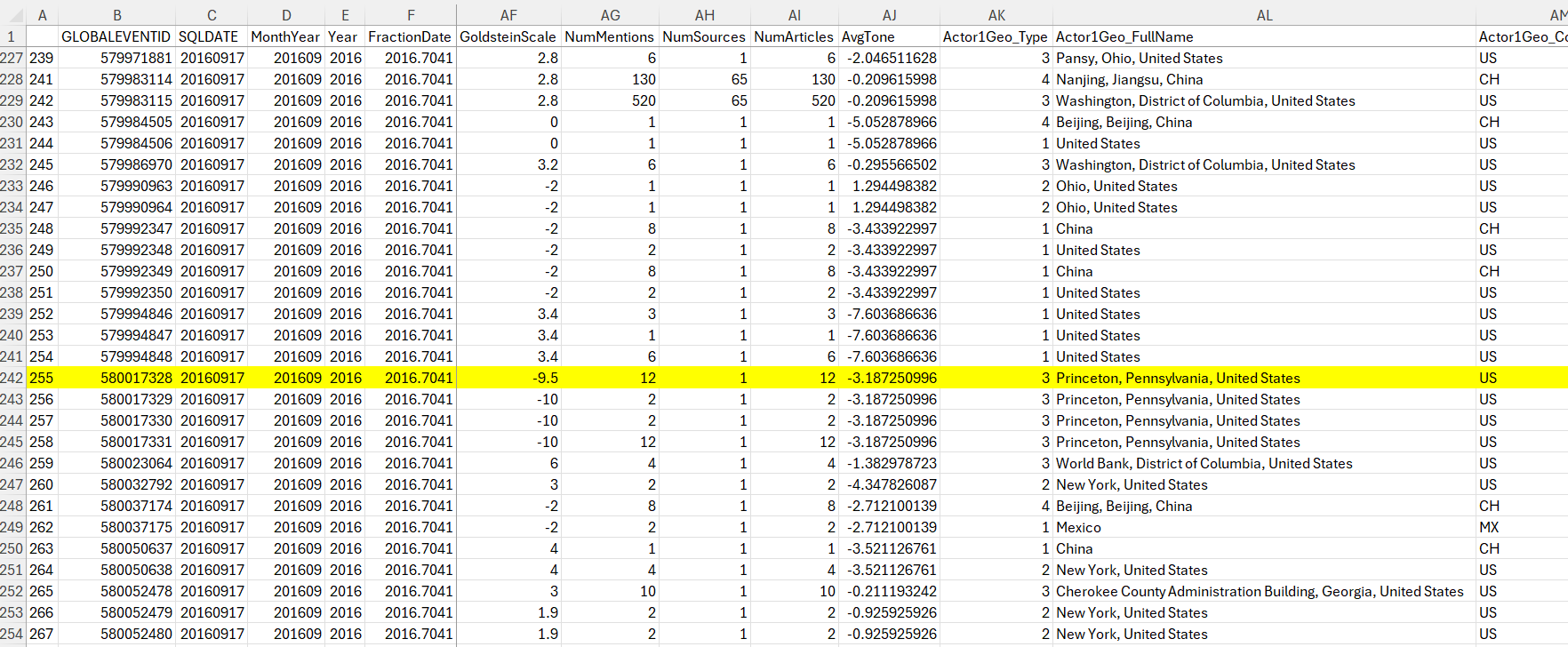
I can focus on a particular event where the Goldstein score was particularly negative, as we have the web link for the news:
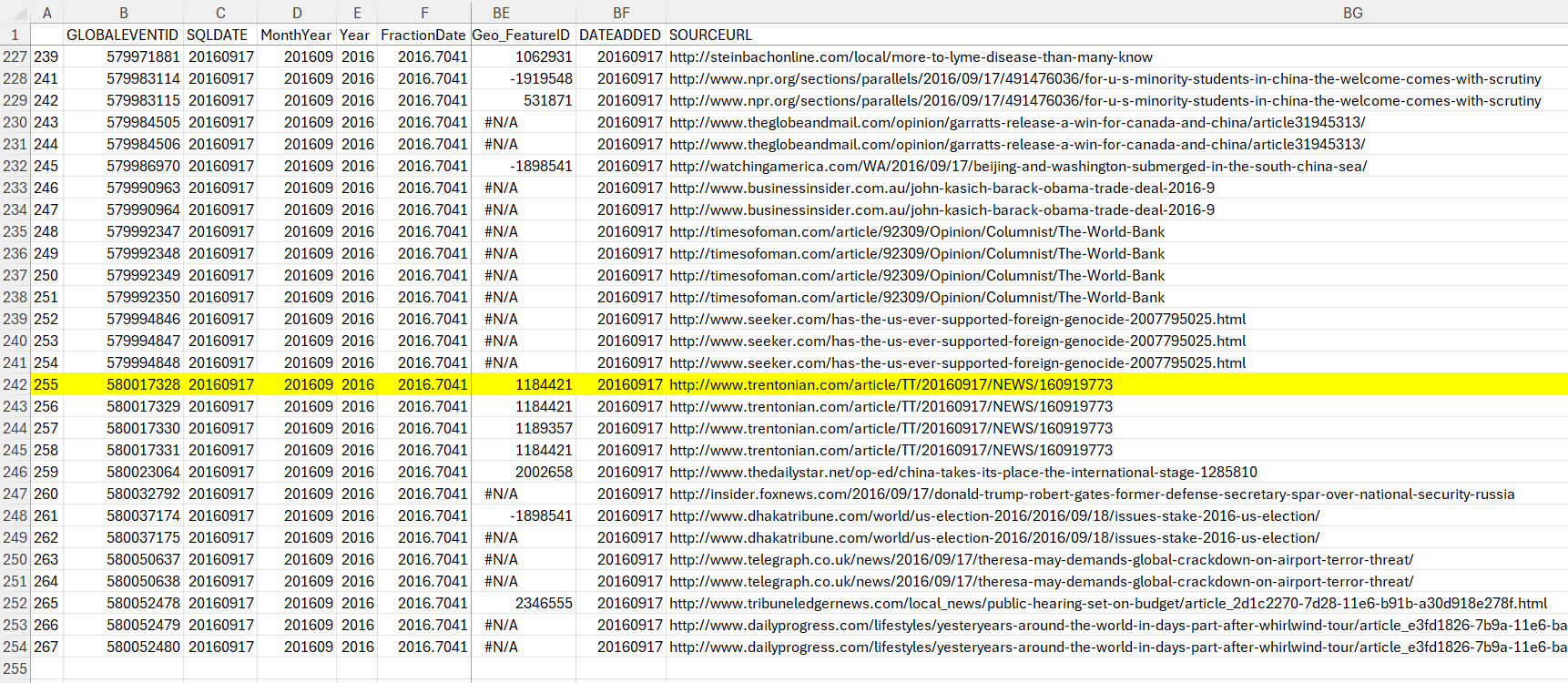
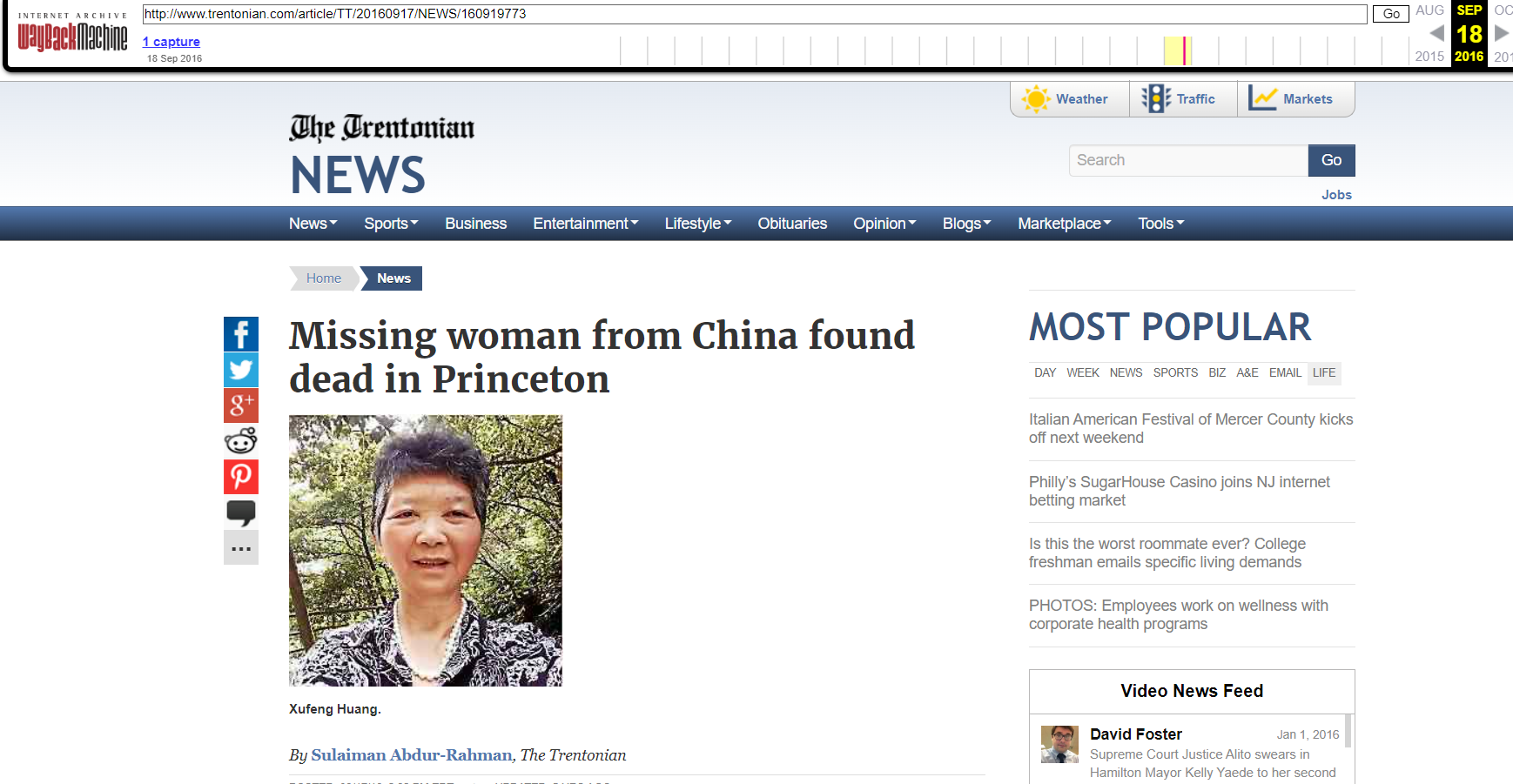
In the Wayback Machine, you can locate the original source for the news:
############################################################################
install.packages("GDELTtools")
library(GDELTtools)
data <- GetGDELT(start_date="2016-09-26", end_date="2016-09-26",
row_filter=Actor1Code=="USA" & Actor2Code=="CHN",
contains("date"), starts_with("actor"))
data1 <- GetGDELT(start_date="2016-09-26", end_date="2016-09-26",
row_filter=Actor1Code=="USA" & Actor2Code=="CHN")
library(xlsx)
write.xlsx(data, "C:/Users/jamel/Documents/GitHub/EconMacroBlog/Start_GDELT_Data")
write.xlsx(data1, "C:/Users/jamel/Documents/GitHub/EconMacroBlog/Start_GDELT_Data")
############################################################################As we have seen in this blog, it is possible to start straightforwardly with GDELT data. The files for replicating the results in this blog are available on my GitHub.
2 Comments
[…] Starting with GDELT data API with GDELT data at the regional level […]
[…] Starting with GDELT data […]