In this post, I will show you how to reshape ICRG data faster. The International Country Risk Guide (ICRG) dataset is maintained by the PRS group. In their Tables, they provide risk rating on several dimensions like:
- The Political Risk Rating;
- The Economic Risk Rating;
- The Financial Risk Rating;
- The Composite Risk Rating;
- Risk Forecasts.
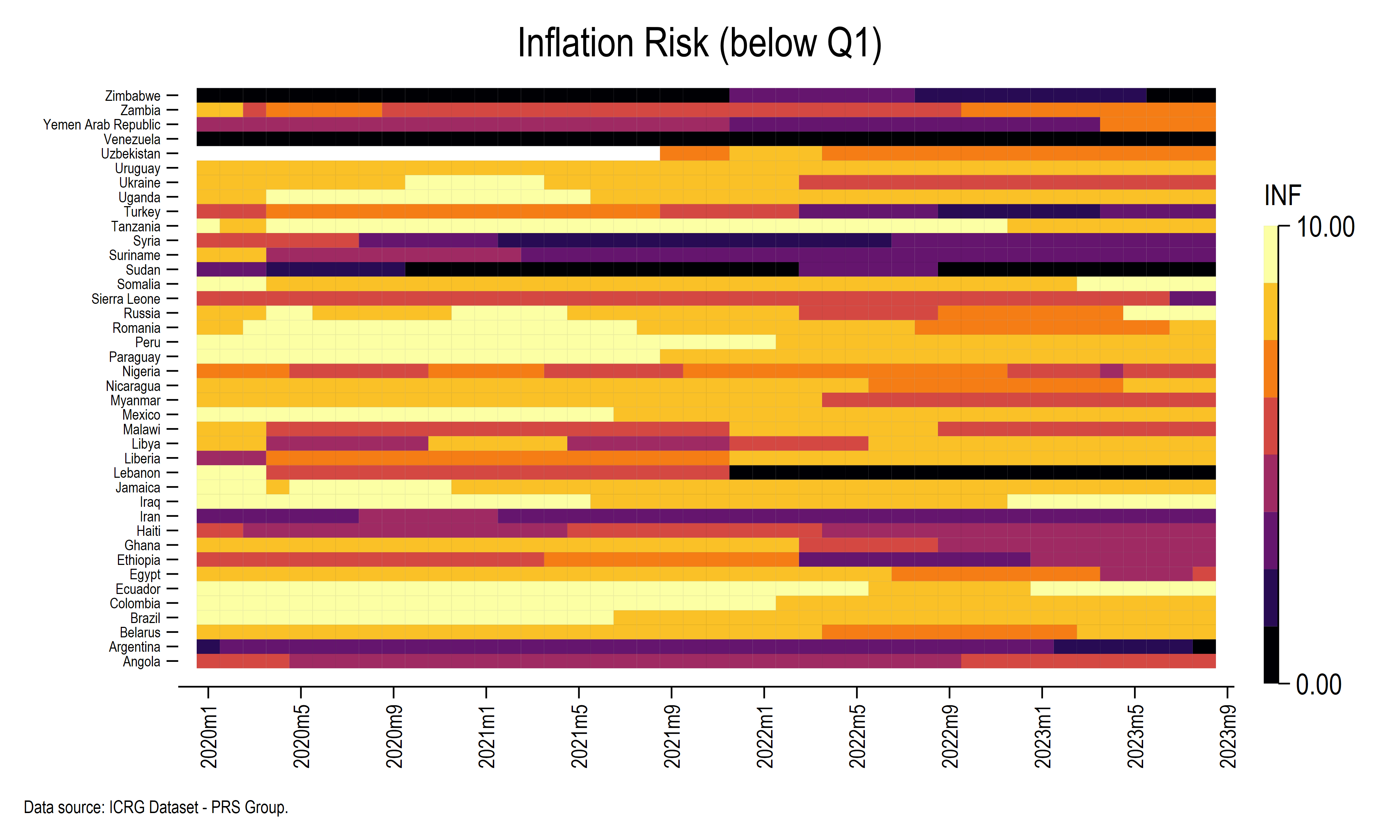
Today, I will focus on the economic risk rating component. In particular, I will take a closer look at the inflation risk variable. In their methodology note, they mention that inflation risk is computed as a score for the estimated annual inflation rate (the unweighted average of the Consumer Price Index) calculated as a percentage change. If annual inflation is below 2 percent, the score is 10 (best); between 19.0 and 21.9 percent, the score is 5; and if the annual inflation rate is above 130 percent, the score is 0 (the worst). See below the heat maps for the inflation risk below the first quartile of average values of inflation risk over the full sample (the code for the heat map is available at the end of this blog, see this post).
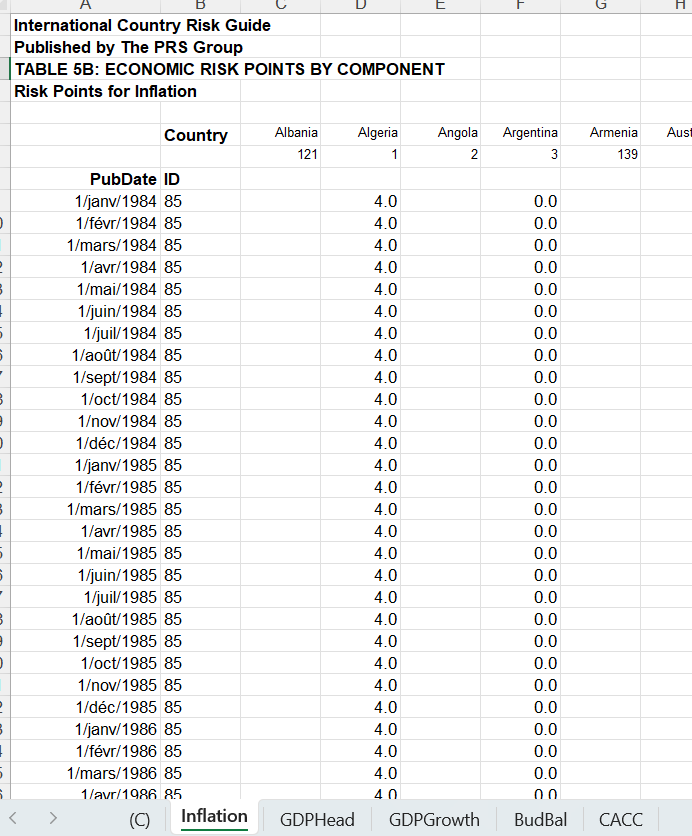
Let me start with some Stata coding. Please note that these datasets are proprietary, so I will not post them on my GitHub. The Table looks like this:
The objective will be to put these data in panel data format thanks to the writing of an efficient (short) code. Put the data in the same folder, as you Stata Do-file. First, import the data with:
**# ************ INFLATION *************************************
cd C:\Users\jamel\Dropbox\Latex\PROJECTS\
cd 23-10-ICRG-Data\ICRG_T5B\
import excel ///
"ICRG_T5B.xlsx", ///
sheet("Inflation") cellrange(A6:ES484) firstrow clear 
In addition to creating a time variable in Stata format (see this post), I will drop the second column and the second row with:
drop in 1/2
drop A Country
display tm(1984m1)
gen time = 287+_n
order timeThen, I will use this suggestion made by Nick Cox to create a series of variable names with the name of the variable and the name of the country. In order to ease the reshaping part:
ds time, not
foreach v in r(varlist)' { renamev' INF_`v'
}
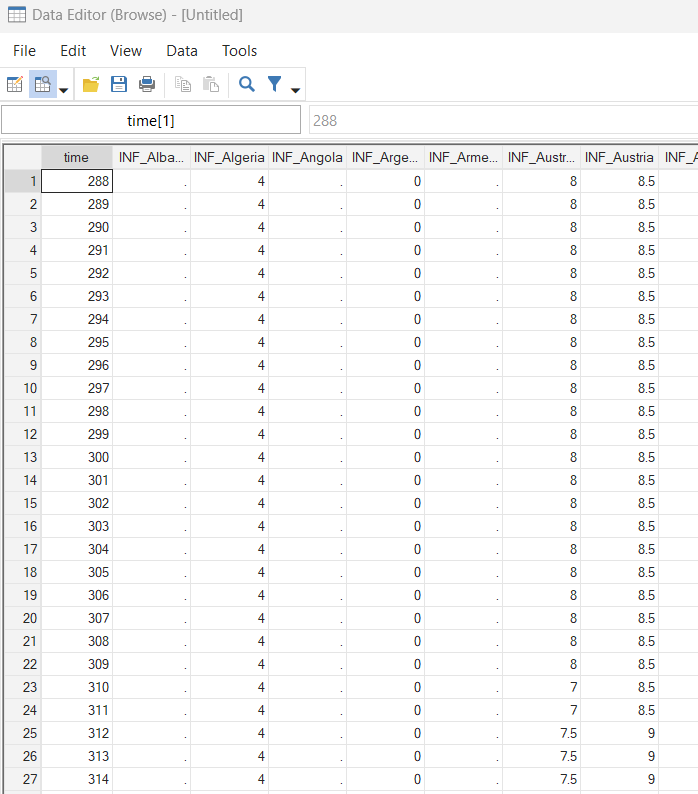
I reshape the data and “destring” the variable for Hungary (it is unclear to me why the variable was in string format for Hungary):
destring INF_Hungary, replace
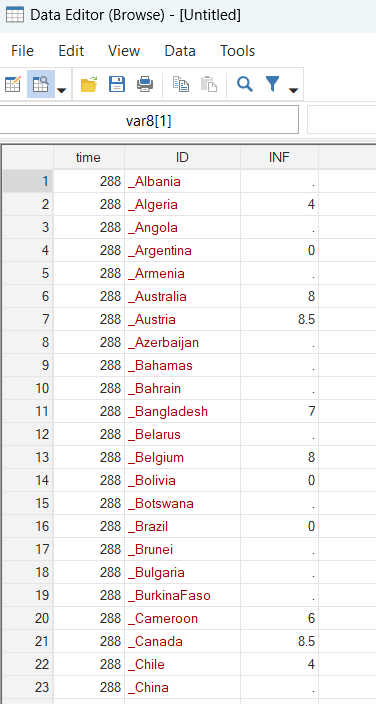
reshape long INF, i(time) j(ID) stringI made some progress, but the results are not yet ready to use:
I will use a variation of the previous code snippet in order to produce the country names, and format the time variable:
ds time, not
capture foreach v in `r(varlist)' {
split `v', p(_)
}
format %tm time
rename ID2 country
order time country INF, first
keep time country INF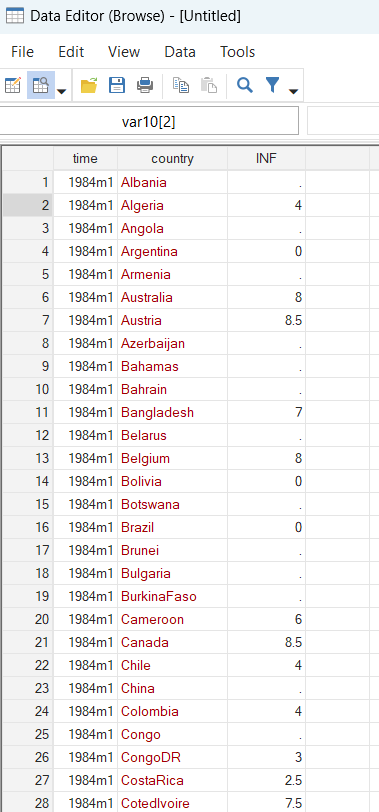
In order to keep the country that have a space in their names, I apply the following code snippet:
replace country = "Burkina Faso" if country == "BurkinaFaso"
replace country = "Congo DR" if country == "CongoDR"
replace country = "Cote d'Ivoire" if country == "CotedIvoire"
replace country = "CzechRepublic" if country == "CzechRepublic"
replace country = "Dominican Republic" if country == "DominicanRepublic"
replace country = "El Salvador" if country == "ElSalvador"
replace country = "New Zealand" if country == "NewZealand"
replace country = "Papua New Guinea" if country == "PapuaNewGuinea"
replace country = "Saudi Arabia" if country == "SaudiArabia"
replace country = "Sierra Leone" if country == "SierraLeone"
replace country = "South Africa" if country == "SouthAfrica"
replace country = "South Korea" if country == "SouthKorea"
replace country = "Sri Lanka" if country == "SriLanka"
replace country = "Trinidad and Tobago" if country == "TrinidadTobago"
replace country = "United Kingdom" if country == "UnitedKingdom"
replace country = "United States" if country == "UnitedStates"Then, I will the kountry package to produce the IMF codes. This package has been covered in previous posts of mine on the use of DBnomics with Stata. I make some adjustments for the country names, and save the data:
kountry country, from(other) stuck marker
list if MARKER==0
// Congo, DR - Czechoslovakia - Korea, DPR
rename _ISO3N_ iso3n
drop MARKER
kountry iso3n, from(iso3n) to(imfn) marker
list if MARKER==0
rename _IMFN_ imfcode
drop NAMES_STD MARKER
kountry imfcode, from(imfn) marker
// Drop USSR - Serbia - Serbia & Montenegro + MARKER == 0
drop if country == "USSR"
drop if country == "Serbia"
drop if country == "Serbia & Montenegro"
/*
isid imfcode period
duplicates report imfcode period
duplicates list imfcode period
*/
drop if country == "East Germany"
drop if country == "West Germany"
drop if MARKER == 0
drop country
rename NAMES_STD country
rename time period
order country period imfcode
drop iso3n MARKER
encode country, gen(cn)
label list cn
xtset imfcode period
xtdes
save "INF.dta", replaceThe final result:

// Run everything between preserve and restore
preserve
drop if period<tm(2020m1)
format %tm period
summ period
local x1 = `r(min)'
local x2 = `r(max)'
heatplot INF i.cn period if mean_INF <7, ///
yscale(noline) ///
ylabel(, nogrid labsize(*0.5)) ///
xlabel(`x1'(4)`x2', labsize(*0.75) angle(vertical) nogrid format(%tmCCYY!mnn)) ///
color(inferno) ///
levels(8) ///
ramp(right space(14) format(%4.2f)) ///
p(lcolor(black%10) lwidth(*0.1)) ///
ytitle("") ///
xtitle("", size(vsmall)) ///
xdiscrete name(INFQ3, replace) ///
title("Inflation Risk (below Q1)") ///
note("Data source: ICRG Dataset - PRS Group.", ///
size(vsmall))
restore
graph export INFQ3.png, as(png) width(4000) replace